Praegustator
Egy ideje elkezdtem egy régóta halogatott projektemen dolgozni. Ez egy olyan program lesz, ami gépi tanulás (jobban hangzik mint a statisztika 😉) segítségével fogja a híreket kategorizálni, előszűrni számomra. Legalábbis egyelőre ez a célom. Ezért lett a neve Praegustator.
Mivel még erősen fejlesztés alatt áll a program, és a feldolgozó csővezeték még sokat változhat, ezért a letöltött cikkeket mentem, hogy amennyiben módosítom a feldolgozó futószalagot, akkor meg tudjam ismételni a feldolgozást, és a modellt az új kimenet alapján újra tudjam tanítani.
Közel egy hónapja fut már egy verzió tesztüzemben, és több mint 1GB már az adatbázis mérete. Megvizsgálva az adatbázist több tanulságot levontam. Egyfelől az adat felét a mentett cikkek törzsei teszik ki, másfelől a kinyert szöveg-jellemzők tárolási formátuma is erősen pazarló.
Mivel a szöveg-jellemzők valószínűleg SQL lekérdezésekkel (is) feldolgozva lesznek, ezért ott egy tömörített bináris blobban tárolás nem megoldás a helytakarékosságra, ezért ott inkább a reprezentáció finomhangolásával nyertem némi helyet.
A cikkek szövegtörzsét azonban csupán mentéskor egyszer írom, és csak akkor olvasom, amikor egy módosítás után a szöveg-elemző futószalagban az elemzés kimenetelét újra kell generálni. A feldolgozás nem SQL-ben, hanem a C# alkalmazásban történik.
Ezen szempontok figyelembevételével úgy döntöttem, hogy az eddig szövegként tárolt HTML szövegtörzs helyett azt tömörítve fogom tárolni. Már csak a tömörítési eljárást kellett kiválasztani.
A Weissmann-átlag
A Silicon-Valley című méltán sikeres amerikai vígjáték sorozat első évadjában lehetett a veszteségmentes tömörítések jellemzésére használt – a sorozat kedvéért megalkotott – Weissmann-átlaggal (angolul Weissman-score) találkozni.
Mivel nagyon professzionális vagyok, ezért úgy döntöttem, hogy a tömörítési eljárás kiválasztását illendő lenne empirikus úton, mérésekre alapozva végezni, de jó móka lenne ezt a Weissmann-átlagot is kiszámolni.
A Weissmann-átlag, amint már írtam, egy film kedvéért kitalált áltudományos mérőszám, veszteségmentes tömörítő algoritmusok összehasonlítására.
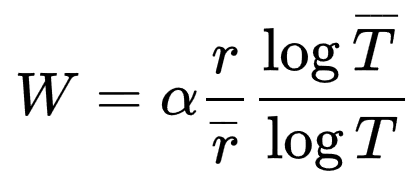
A képletből látható, hogy ez abszolút összehasonlításra sajnos nem igazán alkalmas, legalábbis a referencia értékek (skálafaktor, tömörített adatok, referencia algoritmus tömörítési aránya és futásideje) megadása nélkül.
A mérés
Mivel az alkalmazásom .Net Core 2.0 alapon fut, így eredetileg ott mértem meg az elérhető algoritmusok teljesítményét.
A következő algoritmusokat vetettem össze:
- Gzip – a .Net keretrendszer részeként elérhető
- Deflate – szintén elérhető a keretrendszer részeként, a Gzip algoritmus ezen alapul
- Bzip2 – Linux alatt népszerű, a gzipnél tömörebb, de lassabb algoritmus. Mivel a keretrendszer nem szállítja, ezért egy külső managelt könyvtárral próbáltam ki: [SharpZipLib 1.0.0-alpha2(https://www.nuget.org/packages/SharpZipLib/1.0.0-alpha2). Natív kóddal feltehetően gyorsabb lenne.
- Brotli – A Google új üdvöskéje. Natív .Net Core megvalósítás: BrotliSharpLib 0.2.1
A keretrendszer következő, 2.1-es verziója azonban natív Brotli támogatást fog hozni, így átálltam egy előnézeti verzióra, hogy annak a teljesítményét is össze tudjam vetni a többi versenyzőével. Így a Brotli kétszer is szerepel a mérésekben.
Minden algoritmusnak vannak különféle beállításai. Én mindegyiknél a leggyorsabb és legtömörebb módokat próbáltam ki, nem finomhangoltam egyiket sem.
A méréseket egy ~80 MB méretű adatbázis mentésből kinyert korpuszon végeztem. Az adatok mentett HTML dokumentumok, magyar és angol nyelveken vegyesen.
A mérést nem mikrobenchmarkként végeztem, nem ismételtem meg többször, nem számoltam szórásokat. Nekem most elég jó volt egy egyszerűbb mérés is.
Eredmények
Az eredményeket a mérőprogram csv formátumban elmentette.
Adat elemzés, egy csipetnyi Excel gyűlölettel
Az adatok feldolgozásához úgy döntöttem, hogy kipróbálom az Excelt. Elég kevéssé ismerem, és vannak, akik erre esküsznek. Nekem eddig csak csalódásokat okozott, mindig jobban működött egy Python scriptet összedobni, mint a táblázatkezelővel szenvedni, de még programozó kollégák is azt állítják, hogy van, hogy az Excel legjobb választás adat turkálásra. Gondoltam adjunk még egy esélyt neki!
Kipróbáltam.
Tévednek.
Amennyit küzdöttem vele, az alatt Python segítségével többször is elvégeztem volna amit akartam, és így sem vagyok teljesen elégedett a kapott grafikonokkal. Az adatból másfajta adatok kinyerésével nem is próbálkozom már, annyira körülményes, elmásznak az oszlopnevek, meghülyülnek a képletek.
A transzponálással külön meg kellett küzdenem. Szánalom.
- Jelölj ki egy pont akkora területet mint a transzponálandó transzponáltja!
- Ne nyomj entert,
- hanem nyomj Ctrl+Shift+Entert!
A CSV import elég awkward, és frissíteni sem lehet lehet könnyen, de azért adatkapcsolatként szerepel, amit törölni kell és újra betölteni a filet egy újabb mérés után. Egy Python script esetében ez felnyíl-enter lenne. Ehelyett 20 kattintás, ha más a sorok száma, akkor képletek frissítgetése…
Most képzeljük el, hogy szórásokat is számoltam volna, több adatsort kellett volna korreláltatni hozzá azonos elem különböző méréseiből. Erre teljesen alkalmatlan eszköz az Excel.
Egy olyan scatterplot, amiben van értelmes jelmagyarázat is, és címkéi is vannak az adatpontoknak… Feladtam ott, hogy legalább a pontokra sikerült felrakni a címkéket.
További számításokat nem végeztem inkább, másfajta plotokat sem készítettem. Egyszerűen alkalmatlan komolyabb adatfeldolgozásra. Varázsbillentyűk. Képlet frissítés után gondosan copy-pastelni végig a sorban/oszlopban. Nem értem milyen elme tud így gondolkozni. Nincs absztraháló ereje, teljesen ad-hoc, átláthatatlan. Vagy valaki olyan, akit beleszoktattak ad-hoc hülye eszközök használatába, és ettől torzult az elképzelése egyes munka/kognitív folyamatokról. Talán egy könyvelő? Az adószabályok, a főkönyv számozott-elnevezett kategóriái, és az ÁNYK hasonló pokolbéli kínzóeszközök… Azok után az Excel akár tűnhet is megfelelő eszköznek.
A Weissmann paraméterek
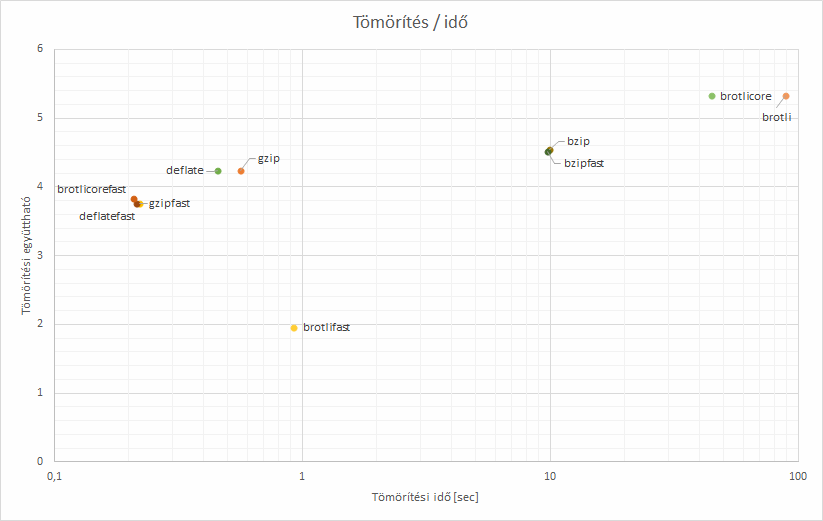
Ahogy a táblázatból is látható, a gzip algoritmus Optimal (linux világban gzip -9) változatát tekintettem referencia algoritmusnak. A skálafaktor értéke α = 1 volt.
Lássuk már az eredményeket
| Algoritmus |
Idő
[sec] |
Tömörítés |
Sebesség
[Mbyte/sec] |
Weissmann átlag
α = 1 |
| gzip |
0,562755 |
4,241916 |
138,625 |
1,0000 |
| gzipfast |
0,221613 |
3,761087 |
352,020 |
0,7391 |
| deflate |
0,457420 |
4,243974 |
170,548 |
0,9579 |
| deflatefast |
0,214454 |
3,762704 |
363,771 |
0,7351 |
| bzip |
9,942345 |
4,549692 |
7,846 |
2,7860 |
| bzipfast |
9,717193 |
4,519541 |
8,028 |
2,7327 |
| brotli |
88,602744 |
5,325078 |
0,880 |
-15,0365 |
| brotlifast |
0,926333 |
1,953454 |
84,216 |
0,5155 |
| brotlicore |
44,596294 |
5,324878 |
1,749 |
19,7554 |
| brotlicorefast |
0,209611 |
3,835408 |
372,175 |
0,7463 |
Ugyanez képen
Végkövetkeztetés
Mivel a Brotli tömörebb, bár nagyságrendileg lassabb, arra esett a választásom. A Gzip általában jó választás, fast módban is egész jól tömörít, nagyon gyorsan, de arra jutottam, hogy mivel elég sok cikket kell majd tárolnom, de nem nagyon nagy tempóban érkeznek, ezért jobban megéri alaposabban tömöríteni. Egy dokumentum tömörítése még így átlagosan is 10ms alatti (A BrotliSharpLib legtömörebb módjával), és jelenleg 15 percenként néhány tucat dokumentum érkezeik csupán. A Brotli kitömörítési sebessége a gzipével összemérhető elvileg, de azt nem mértem meg.
A Brotlit amúgy kifejezetten webes tartalom tömörítésére találták ki, a leggyakoribb angol szavak és HTML tagek is szerepelnek az előre generált szótárában, aminek köszönhetően ilyen tartalmat még hatékonyabban tud tömöríteni. Ezért is gondoltam, hogy most jó választás lehet számomra.
Jelenleg a managelt BrotliSharpLib megoldását használom, majd a framework 2.1-es verziójának kiadása után frissítésekor átállok a Microsoft megoldására, mivel az közel kétszer gyorsabb. A biztonság kedvéért kipróbáltam, és a két megoldás kimenete szinte azonos, méretben is csak néha akad néhány byte eltérés. Egymás kimenetét sikeresen ki tudják bontani. Résen kell lenni, az ördög nem alszik!
PiedPiper
Bár az általam számolt Weissmann átlagokkal a SiliconValley sorozatból ismert értékkel nem lehet közvetlenül összevetni a PiedPiper Weissman számát, én megteszem!
A filmben az érték az elképesztő 5,2-re adódott, amitől mindeki el volt alélva! Ezt azzal érték el, hogy egy 132 GB méretű filet 24,35 GB-ra tömörítettek 12 másodperc alatt.
Nekem a .Net Core 2.1-es Brotli 80MB-ot 15MB-ra tömörített 44 másodparc alatt, és ez 19 pontot ért az én összehasonlításomban
A győztes tehát egyértelműen a… na jó, ennek tényleg semmi értelme :)